Workflow
Case and Task
The ivy workflow manages the execution of process instances. A process instance is represented trough one Case and one or multiple Tasks. The Case exists from the first process step until the last process step and holds information of a process instance. When the Case gets finished even the process gets finished and backwards. A Case is processed though Tasks. Each Task defines an unit of work, which has to be done as one working step. Therefore a Task is assigned to a user or role which executes Task. A Task starts by a process-start element or a task-switch element and ends by the next task-switch element or an process-end element.
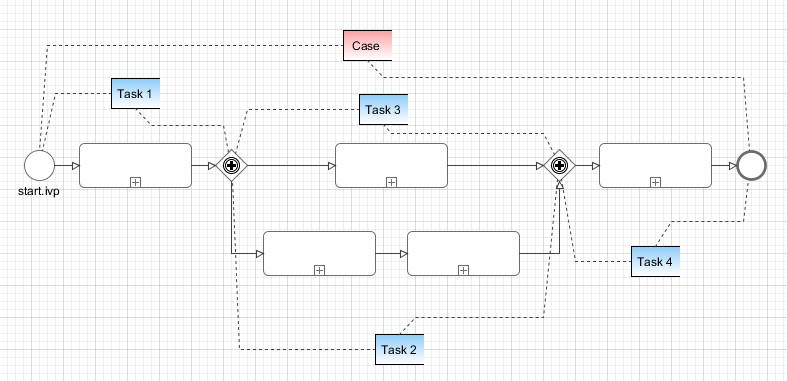
Business Case
Modern processes are loosely coupled and highly adaptive. Business processes can break out of the standard process flow and trigger asynchronous processes or send a signal that starts various other processes. As every running process creates a new Case instance it can get difficult for the workflow users to track the history and context of a task.
To clarify the workflow view, multiple Cases can be attached to a single Business Case. Triggered or signaled process-starts define in their inscription whether the started Case should be attached to the Business Case of the calling Case. Moreover, any Case can be attached to a Business Case by API. If a case map is started a business case is automatically created. See Workflow execution of Case Map Processes.
Lifecycle
The first case of a process always acts as Business Case (see image ‘Initial Case’). If later an additional process case is attached to this initial case, this first initial case will be copied and treated as Business Case (see image ‘Multiple Cases’).
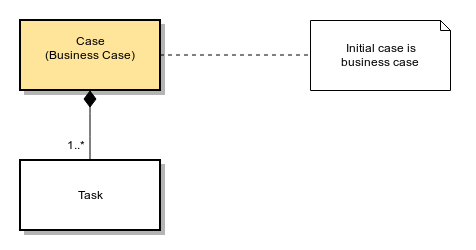
Initial Case
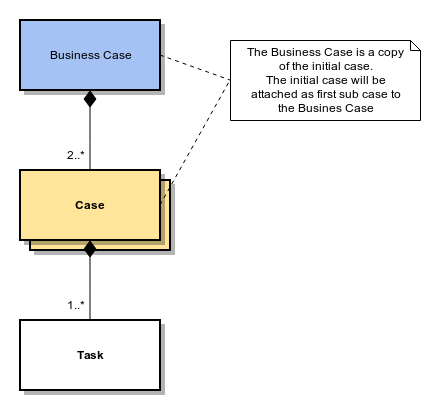
Multiple Cases
Case and Task Categories
A Case or a Task can be assigned to a category. A category is a
structured String (e.g. Finance/Invoices) and categorize them into a
hierarchical structure. It is beside the name of a Task (or Case) an
important identification attribute of a Case or Task.
The Category API allows to get localized information from the CMS.
E.g. the name of the category Finance/Invoices is stored in the
CMS at /Categories/Finance/Invoices/name.
The following example shows a simple usage of a category on Case level. The API on Task level is identical.
ivy.case.setCategoryPath("Finance/Invoices");
String categoryName = ivy.case.getCategory().getName(); // EN: "Invoices", DE: "Rechnungen"
String categoryPath = ivy.case.getCategory().getPath(); // EN: "Finance/Invoices", DE: "Finanzen/Rechnungen"
Tip
The project WorkflowDemos demonstrates the usage of case and task categorisation. Typically the case category is used to categorize the over-all process (i.e. Business Case) and the task category is used to categorize a single or set of unions of work. Because the clear separation of case and task categorization even complex use cases could be handled.
E.g. in a midsized company the process to request an address from a customer change exists in multiple forms. There is one in the customer portal and one for partner agencies. The process executed from the customer portal has the case category ‘CustomerPortal/AddressChange’. The process executed by a partner agency has the case category ‘Partner/Customers/AddressChange’. Both processes has involved a task to validate the address. Finally the address verification is done by the same department/user. So this task has in both cases the category ‘AddressVerification’. This allows the user to filter those tasks no matter where they where created.
Workflow API
There are several APIs to manipulate and query workflow tasks and cases.
Task and Case queries
The fluent workflow query API makes queries against all existing tasks and cases possible. The queries can be written in a SQL like manor.
import ch.ivyteam.ivy.workflow.query.TaskQuery;
import ch.ivyteam.ivy.workflow.ITask;
// create a new query
TaskQuery query = TaskQuery.create()
.aggregate().avgCustomDecimalField1()
.where().customVarCharField1().isEqual("ivy")
.groupBy().state()
.orderBy().customVarCharField2().descending();
// resolve query results
List<ITask> tasks = ivy.wf.getTaskQueryExecutor().getResults(query);
To resolve all tasks that the current user can work on use the following code:
TaskQuery query = TaskQuery.create()
.where().currentUserCanWorkOn()
.orderBy().priority();
List<ITask> userWorkTasks = ivy.wf.getTaskQueryExecutor().getResults(query);
To execute a query an instance of a IQueryExecutor is needed. It can be retrieved trough the ivy environment variable.
// Application specific query executors can be retrieved from the application context
ivy.wf.getTaskQueryExecutor().getResults(taskQuery);
ivy.wf.getCaseQueryExecutor().getResults(caseQuery);
Warning
Queries over all applications can be executed on the global workflow context. But queries that involve the current session could deliver useless results as users are not shared over multiple applications.
ivy.wf.getGlobalContext().getTaskQueryExecutor().getResults(taskQuery);
ivy.wf.getGlobalContext().getCaseQueryExecutor().getResults(caseQuery);
Task and Case manipulation
The API to manipulate tasks and cases is available trough the ivy environment variable.
ivy.case(ICase): represents the current process under executionivy.task(ITask): represents the user’s current work unit in the process under execution.ivy.wf(IWorkflowContext): addresses all workflow tasks and cases of all users for the application under execution.ivy.session(IWorkflowSession): gives access to all workflow tasks and cases of the current user.
REST API
There is a REST API available that uses HTTP, JSON (application/json) as content type and HTTP basic as authentication method. Over this interface the following services are available:
- HTTP GET /ivy/api/{application name}/workflow/processstarts
Returns all process starts that can be started by the authenticated user.
- HTTP GET /ivy/api/{application name}/workflow/task/{taskId}
Returns the task with the given task identifier.
- HTTP GET /ivy/api/{application name}/workflow/tasks
Returns the tasks the authenticated user can work on.
- HTTP GET /ivy/api/{application name}/workflow/tasks/count
Returns the number of tasks the authenticated user can work on.
- HTTP GET /ivy/api/{application name}/engine/info
Returns the version and the name of the engine
Workflow States
During a process execution the corresponding case and tasks have various states. Normally, a case is started non persistent. This means it is stored in memory only. As soon as the process hits a task switch the case and its tasks will be made persistent by storing them to the system database. Only persistent cases and tasks can be resolved with the query API’s above.
Process without Task switch

Process start |
Process end |
|
|---|---|---|
Case state |
CREATED |
DONE |
Task state |
CREATED |
DONE |
Persistent |
NO |
NO |
Process with session timeout
Process start |
User Dialog |
|
|---|---|---|
Case state |
CREATED |
ZOMBIE |
Task state |
CREATED |
ZOMBIE |
Persistent |
NO |
NO |
Process with Task switch
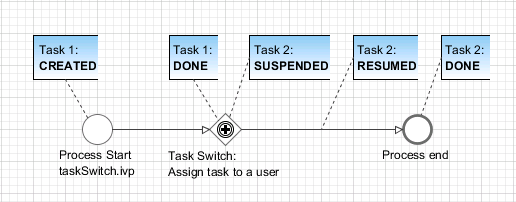
Process start |
Task switch |
Process end |
|
|---|---|---|---|
Case state |
CREATED |
RUNNING |
DONE |
Task state (Task 1) |
CREATED |
DONE |
|
Task state (Task 2) |
SUSPENDED |
DONE |
|
Persistent |
NO |
YES |
YES |
Task switch states in detail
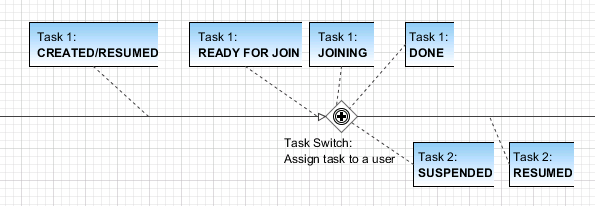
In detail the tasks are going to more technical task states inside of a task switch element. After a task reaches a task switch it is in state READY_FOR_JOIN. As soon as all input tasks have arrived at the task switch the state of all input tasks are switched to JOINING and the process data of the tasks are joined to one process data that is used as start data for the output tasks. After joining the input tasks are in state DONE and the output tasks are created in state SUSPENDED.
Before Task switch |
Task switch (reached) |
Task switch (entry) |
Task switch (done/out put) |
After Task switch |
|
|---|---|---|---|---|---|
Case state |
CREATED/R UNNING |
RUNNING |
|||
Task state (Task 1) |
CREATED/R ESUMED |
READY_FOR _JOIN |
JOINING |
DONE |
|
Task state (Task 2) |
SUSPENDED |
RESUMED |
|||
Persisten t |
NO/YES |
YES |
Task with session timeout
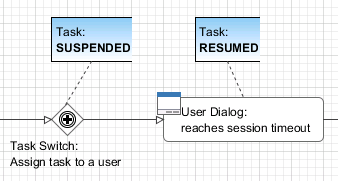
If a user resumes a task with an user dialog and then the session of the user timeouts then the task state is set back to state SUSPENDED and the process of the task is set back to the task switch element.
Task switch |
User Dialog |
Task switch (after session timeout) |
|
|---|---|---|---|
Case state |
RUNNING |
RUNNING |
RUNNING |
Task state (Task 1) |
SUSPENDED |
RESUMED |
SUSPENDED |
Persistent |
YES |
YES |
YES |
User Task
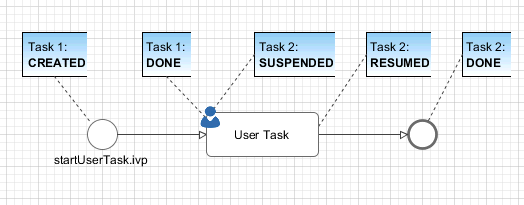
A User Task is the combination of a Task Switch Event and a User Dialog. When the user start working on a normal Html User Dialog the task changes its state to RESUMED. In case of an ‘Offline Dialog’ the task state is not changed before the user submits the task form. Then the state changes from SUSPENDED to RESUMED. Subsequent steps are executed until the task is finally DONE. See also Offline Tasks.
Signal Boundary Event
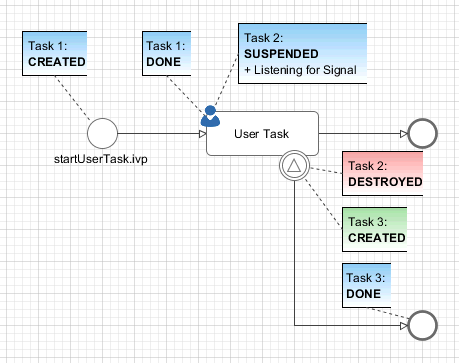
A User Task with an attached Signal Boundary Event is listening to a signal while its task is in SUSPENDED state. If the signal has been received the task is destroyed and the execution continues with a newly created follow-up task.
Case Map with session timeout
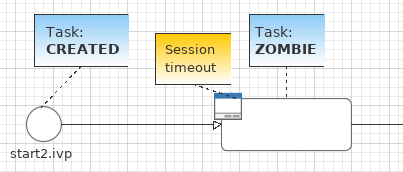
When a task is created by Case Maps, its initial state is CREATED and it is immediatly persisted to the database. If the session of the user expires while working on this initial task, its state is being reset to ZOMBIE. The same goes for the Case and Business Case.
Process start |
User Dialog |
|
|---|---|---|
Case state |
CREATED |
ZOMBIE |
Task state |
CREATED |
ZOMBIE |
Business Case state |
CREATED |
ZOMBIE |
Persistent |
YES |
YES |
Other task states
There are more task states mainly for task synchronisation, error
handing, intermediate events, or user aborts. To learn more about task
states see enumeration ch.ivyteam.ivy.workflow.TaskState in public
API.
Business Calendar
A business calendar defines the official business hours and business days of an application. Business calendars are organized in a tree structure, with a root calendar defining the application default values and child calendars inheriting all values from their ancestor, e.g.
AxonIvyGlobal
Switzerland
Zurich
Zug
Austria
Germany
Above you see the business calendar definitions for AxonIvy. We define a global root with three countries. For Switzerland we also add two regions, Zurich and Zug, each with their local public holidays besides the ones they inherit from Switzerland and AxonIvyGlobal.
You can use business calendars, through the IBusinessCalendar API to make calculations related to business days or business hours. This is very useful for process steps that need to work with business days, rather than with normal days.
For example:
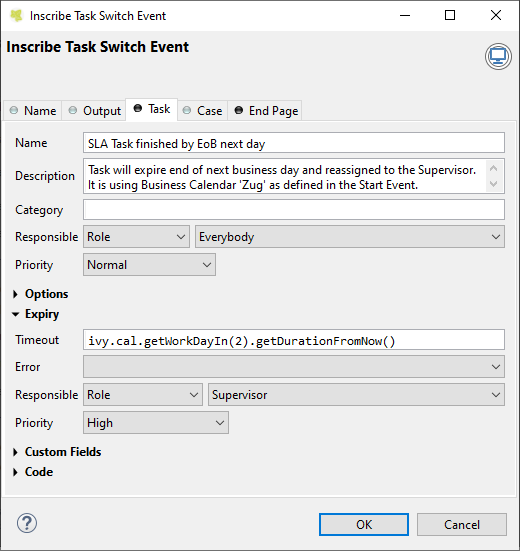
A Service Level Agreement (SLA) defines that a task needs to be processed by the end of the next business day. This can be implemented by setting the task expiry to the business day after the next.
Set the desired business calendar on the case if the default calendar does not apply:
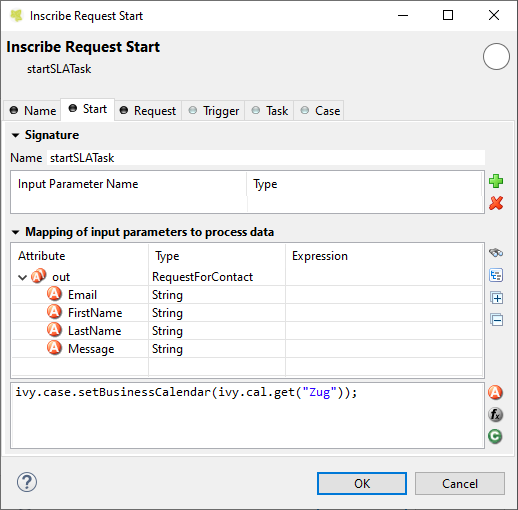
Then set the timeout duration to two business days, using the current calendar.
A payment application automatically corrects an entered payment date to the next business day if necessary:
// e.g. on the Start tab of a Request Start Inscription Mask out.paymentDate = ivy.cal.getWorkDayIn(out.paymentDate, 0);
You can set a calendar on tasks, cases, environments or applications. The variable (ivy.cal) references the calendar that is valid for the current context with the following priority:
current task, if any is set
current case, if any is set
current environment, if any is set
current application, if any is set
root calendar of the current application
You can use another calender by referencing it by its name:
ivy.cal.get("Zug").getWorkDayIn(2);
If you want to configure business calendars for test purposes in your
Designer environment you can change (or create if it doesn’t exist yet)
the app-designer.yaml file in folder <designer_path>/configuration. Note
that all values in this file are valid for all projects in your
workspace and that they don’t get cleared after a restart.
See chapter Business Calendar in the Engine Guide on how to configure business calendars on your Engine instance.