Miscellaneous
This chapter deals with several concepts and features that are integrated into Axon Ivy to leverage user convenience and experience.
Data Caching
Axon Ivy offers a feature to store data temporarily into a data cache in the engine’s memory. If you want to read data that stays unchanged for some time, you do not need to re-read the data every time you need to access it. If this data is read by long-running queries from a database or by calling a slow web service, you can gain a lot of performance by caching this data. The DB Step and the Web Service Call Activity natively support Data Caching (see the Data Cache Tab for more information), for other data you can access the Data Cache API by IvyScript.
Caches
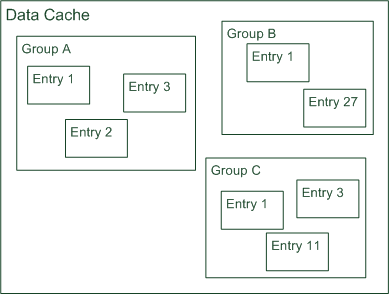
Data that is cached is always stored in a data cache entry. This can be the result of a database query or of a web service call if you use the Data Cache Tab on the DB Step or on the Web Service Call Activity. But you can also store any arbitrary object into a data cache entry by using the Public API. Entries are identified by a textual entry identifier.
Entries are organized into groups. An entry always belongs to exactly one group, you cannot store the same entry in more than one group. In other words, the identifier of an entry must be unique in its group. If two entries in the same group have the same identifiers, then they are identical. Like entries, groups are as well identified by a textual group identifier. Use groups to store cache entries with similar data. This simplifies the invalidation of related data, see chapter invalidation below.
A Data Cache is a container for multiple groups. The identifier of a group must be unique in its data cache. If two groups in the same Data Cache have the same identifiers, then they are identical.
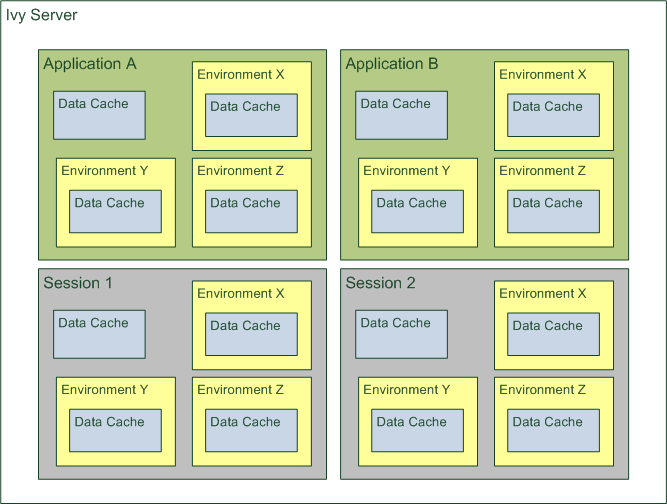
Data Caches always have a scope. A scope defines the boundaries of a specific Data Cache and as well the life cycle of the Data Cache depends on its scope:
Scope |
Type of cached data |
Multiplicity of Data Cache |
Data Cache life cycle start |
Data Cache life cycle end |
|---|---|---|---|---|
Appl icat ion |
Global data that is related to the application |
One per application |
Application creation or engine start |
Application deletion or engine stop |
Envi ronm ent |
Global data that can vary for different environments, e.g. if you are using tenants or different configuration s |
One per application and environment |
Environment creation or engine start |
Environment deletion, application deletion or engine stop |
Sess ion |
Data that is related to interactions within the actual session |
One per session and environment |
Session start |
Session end |
Access and Life Cycle
Cache entries and groups are created the first time they are accessed - the first time the process step with the data cache entry is executed - and they are destroyed when the scope of cache entries or groups reach the end of their life cycle. For the scope Session this is the logout of the user of the session or the session timeout, for the scopes Application and Environment this is when the application is terminated or inactivated.
Cache entries and groups are resolved by their identifiers. You can put different cache entries into one group by using the same group identifier for all entries. You can use the same data cache entry for multiple steps by using the same group and the same entry identifier for all entries. This is very useful for data that almost never changes, you can load the data into the cache once at the beginning of the scope’s lifetime and read it from the cache from every step in all processes thereafter.
Invalidation
In order to take into consideration changes in the data that is handled by the cache entries, it is possible to invalidate cache entries and as well whole groups either on request or after a configurable period of time. Thereby, invalidation means that only the value of the data cache entry is deleted, but not the entry itself. The next time a step referring to this data cache entry is executed, the value of the data cache is loaded again.
You can invalidate an entry, a group and even the whole cache explicitly in the Data Cache Tab of inscription masks of the process steps that use data caching or by an IvyScript API call. Otherwise you may specify a period as a lifetime or fixed time of day for invalidation. The lifetime period starts when the group/entry is loaded the first time. A background job is responsible to invalidate entries/groups when their lifetime has ended. If you set a fixed invalidation time, the corresponding entry or group is invalidated once per day at that time. By invalidating a group, all its contained entries are invalidated and similarly invalidating the whole data cache does invalidate all groups and therefore as well all entries.
Note
How Data Caching works on an |ivy-engine| Enterprise Edition
An Axon Ivy Engine Enterprise Edition consists of multiple engine instances (nodes) that are running on different machines.
In an Axon Ivy Engine Enterprise Edition the Application and Environment data caches will be created on each node independently. However, if a data cache is invalidated on one cluster node either by timeout or explicitly, then it will be automatically invalidated on all other cluster nodes as well.
On the other hand, Session data caches will only be created on one node because sessions are always bound to a specific node in the cluster.
System Events
Axon Ivy offers the concept of system events, which can be understood as messages that are broadcasted across the Axon Ivy installation. While Axon Ivy itself (e.g. the workflow subsystem) generates events that interested participants may subscribe to (e.g. to be informed when a case is created or finished), it is also possible for implementors to define their own events and to broadcast them to any component that might be interested. Since this mechanism is session- and workflow independent, it can also be used to implement inter-session communication (within the same Application).
Concept and general usage
System events are messages that are broadcasted across the Axon Ivy system and that will be delivered to any interested party. System events have a name and are categorized, and they may carry an optional parameter object. System events can only be sent within the same Application on an Axon Ivy Engine.
Currently two categories are defined:
SystemEventCategory.THIRD_PARTY and
SystemEventCategory.WORKFLOW. The category THIRD_PARTY can be
used to send (and receive) system events that are generated by
integrated third party applications (or processes). The category is
reserved exclusively for this purpose; i.e. the Axon Ivy Engine will
never generate any events of this type.
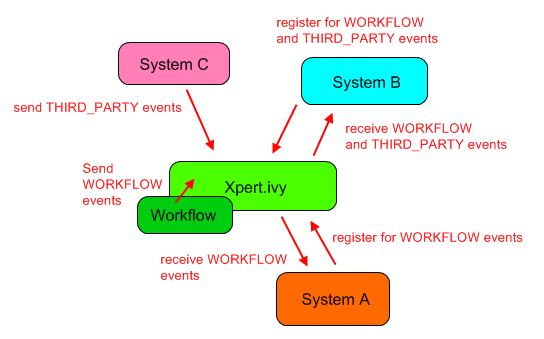
The Axon Ivy system itself currently only generates events of the
category WORKFLOW. Inside this category, events with the following
names are generated:
WorkflowSystemEvent.TASK_CREATEDWorkflowSystemEvent.TASK_CHANGEDWorkflowSystemEvent.CASE_CREATEDWorkflowSystemEvent.CASE_CHANGED
All of those events carry a parameter object of the type
WorkflowSystemEventParameter which gives access to the identifiers
of the workflow objects that have been created or modified. More system
defined categories and events can be expected in the future.
To send system events, client and/or third party applications must first
create a SystemEvent object and then get a hold of an
IApplication object, which offers the method
sendSystemEvent(SystemEvent event). Only events of the category
THIRD_PARTY can be sent by process applications, attempts to send
system events of different categories will result in an error.
To receive system events, clients must implement the interface
ISystemEventListener and must then register themselves on an
IApplication object using the method
addSystemEventListener(EnumSet<SystemEventCategory> categories, ISystemEventListener listener).
It is strongly recommended, that the similar remove method is used, as soon as clients
are no longer interested in a specific event category.
Clients should only listen to system events they know the name of, all other events should be ignored. Clients should handle received events as fast as possible, because handling will block the delivery of events to other receivers. Also the received parameter object should never be modified (it shouldn’t be modifiable in the first place), since this may affect the handling by other receivers which will consequently receive a modified event object.
In Java, the handling of system events generally results in code similar to the following:
/**
* Registers this participant for workflow system events.
*/
public void registerForWorkflowEvents(IApplication application)
{
application.addSystemEventListener(EnumSet.of(SystemEventCategory.WORKFLOW));
}
/**
* Unregister this participant for all system events.
*/
public void unregister(IApplication application)
{
application.removeSystemEventListener(EnumSet.allOf(SystemEventCategory.class));
}
/**
* Implementation of ISystemEventListener.handleSystemEvent(...)
* Events will only be delivered for the categories that this listener registered for
*/
public void handleSystemEvent(SystemEvent event)
{
String eventName = event.getName();
if ("thirdparty.mysystem.myevent".equals(eventName))
{
// do something
}
else if (WorkflowSystemEvent.TASK_CHANGED.equals(eventName))
{
// do something
}
// else: ignore event
}
/**
* Distribute a new system event to all interested/registered listeners of my event.
* MyEventParameter can be of any (serializable) type, the type is part of the event definition,
* clients will have to cast accordingly.
*/
public void sendMyEvent(IApplication application, MyEventParameter param)
{
SystemEvent event = new SystemEvent(SystemEventCategory.THIRD_PARTY, "thirdparty.mysystem.myevent", param);
application.sendSystemEvent(event);
}
Note
How System Events work on an |ivy-engine| Enterprise Edition
An Axon Ivy Engine Enterprise Edition consists of multiple engine instances (nodes) that are running on different machines.
Distribution of system events is handled in two ways on a Engine Enterprise Edition, depending on their category:
THIRD_PARTYsystem events are distributed as cluster messages across all nodes, i.e. from the node that generates the event to all other cluster nodesWORKFLOWsystem events are generated on each cluster node in parallel and then distributed locally only
Important implementation notes:
Since THIRD_PARTY events are distributed as messages in a Cluster,
all custom event parameter objects must be serializable.
Please be aware of the fact that having multiple running instances of a system event sender may lead to race conditions. If you use system events for message exchange between e.g. processes and/or User Dialogs and third party systems that are integrated via the Server Extension mechanism, you should ensure that a certain event is only sent once. This may require that the third party system (e.g. an ESB) is only started on one node in the cluster. Otherwise a received message from the external system may be injected into the Axon Ivy Engine Enterprise Edition system n times (once for each node) instead of being sent only once.
Axon Ivy Search
In a workspace with many large projects it is sometimes hard to find
specific Ivy elements. Then a powerful search mechanism can save the
day. To use the Axon Ivy search, just click on the  symbol in
the toolbar to open the search dialog. In the dialog that opens navigate
to the Axon Ivy tab. At present, searching for
Content Management System, Data Classes, Entity Classes,
Process Models and Process Elements
is supported by Axon Ivy.
symbol in
the toolbar to open the search dialog. In the dialog that opens navigate
to the Axon Ivy tab. At present, searching for
Content Management System, Data Classes, Entity Classes,
Process Models and Process Elements
is supported by Axon Ivy.
Search page
- Search string
Enter here the string you are searching for. You may use two wild-cards: The * (star) for any sequence of characters (may be empty too). and the ? (question mark) for a single character (e.g. a*b matches each entity that starts with “a” and ends with “b” and has 0, 1 or more characters in between whereas a?b matches all strings with a length of three that start with an “a”, end with “b” and has one character in the middle)
- Search For / Search In
Select for what kind of entities you are looking for. Depending on the chosen type, you can specify in which properties of the entity the search string (see above) is searched in. If you select more than one property, then be aware that the search string must occur only in one of the chosen properties.
- Scope
You can decide whether you want to search in the full workspace or only in the enclosing projects (the projects that are selected in the Ivy Project View. If you choose enclosing projects you may select whether you want to include searching in dependent or required projects (see Project Deployment Descriptor chapter for more details about how you can define and use project dependencies). The tool tip text tells which projects are currently selected.
- Recreate indices
The search indices in Ivy are automatically updated if you add, edit or delete entities. However, if you want to recreate the search indices hit this button and all indices are deleted and recreated from scratch in the background. Please be aware, that searching during the time of index creation may not return correct results.
Note
You may use as well other search facilities within this dialog to search for parts that are not covered by the Axon Ivy search page. e.g. if you write your own Java classes in the Axon Ivy Designer you may use the Java search.
Search result view
After clicking on the search button, the search results are collected in the search result view. Double-click on matching entries and the corresponding resource is opened in its editor.
You can change the presentation layout for your search results by selecting a layout from the result view’s menu:
For standard searches, only Project and Namespace grouping is available.
Update Notification
When newer Axon Ivy versions are available a dialog appears after starting Axon Ivy Designer. The dialog contains information about the new versions and where those can be downloaded.
Use the checkboxes provided on the dialog if you don’t want to see the dialog again either for the same versions or for any new versions.
If you want to check for new versions manually use the menu |axon-ivy| > Check for Updates …
Note
While checking for new versions the following statistic information are sent to the update server. These information are only used to improve the product.
Current designer version
Operating system information (name, version, architecture, number of processors)
Java memory information (maximum heap memory, maximum non heap memory)
JVM (Java virtual machine) information (version, vendor, name)
Host information (host name, SHA-256 hashes of IP address and MAC address to identify the host without being able to read the original IP address and MAC address itself)
Eclipse Plugin Mechanism
You need a database frontend in Axon Ivy? Or editing support for any other programming or data declaration languages such as C/C++, PHP or XML? Or you have UML models to view? No problem at all.
Axon Ivy is based on the widely used Eclipse platform which offers a sophisticated plugin mechanism to integrate third-party modules. In these days, Eclipse which originally has been developed as an IDE for Java programmers evolved to a large and vibrant ecosystem and is used for a triad of different tools and systems in almost every work sector. Therefore a huge community exists that offers plugins (open source and commercial) and even web sites (Eclipse Marketplace) for browsing and searching these plugins arose in the past years.
And the conclusion, you can use all these plugins and integrate them into your Axon Ivy installation to interact seamlessly between your favorite plugin set and the built-in Axon Ivy features.
Note
Please follow the installation instructions of the specific plugin to integrate it into your Axon Ivy installation