Common Tabs
This section describes the most common tabs that are used on more than one element inscription mask.
Name Tab
This tab is included in the inscription mask of all process elements and contains the name and a description of the element.
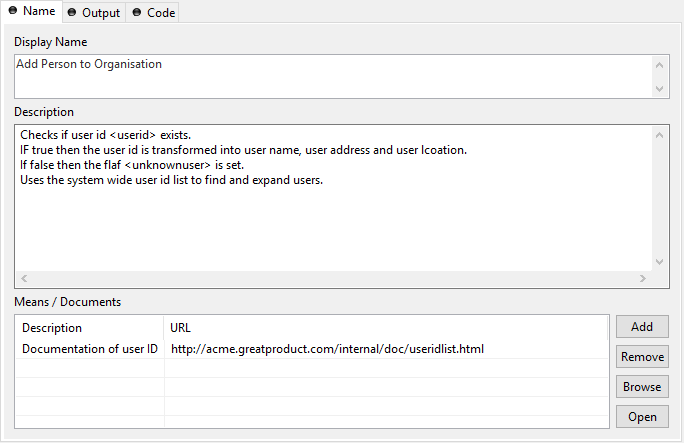
Name tab
- Element Name
Name of the element in the process.
The name will be displayed in the process editor. Various font format options can be chosen on the popup menu of selected text.
Tip
Give each element a name, always. This increases the overview and simplifies the exchange of models between you and your colleagues. If you work in a team, the use of naming conventions is strongly recommended.
- Description
Describes the function of the element.
This text appears as tool tip in the process editor whenever the mouse stays over the element.
- Means/Documents
A list with references to additional stuff that is related to this process step, i.e. documentation, templates, example forms and many more.
Tip
In generated HTML reports, a link is inserted for these document references.
Output Tab
On this tab you can set all values in the output Data Class. By default the output variable is mapped directly to the input variable, but the user can overwrite either the assignment of the whole output Data Class or only of single member of it.
Note
In Axon.ivy input and output of process are always set to the corresponding data class, i.e. in a User Dialog logic element it is the User Dialog Data Class and in a process element it is the project Data Class (or the one which was assigned to the process).
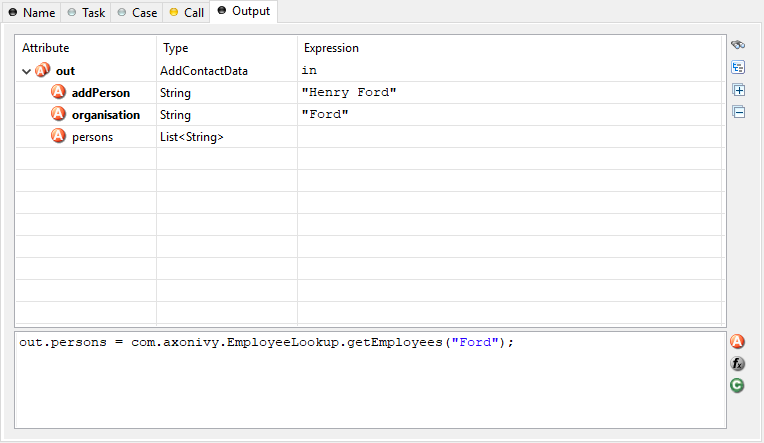
Output tab
- Output Tree
Shows the whole structure of the output variable including each of its members with the assigned values/expressions. You may use the Attribute and Method Browser and the Function Browser to construct the expressions.
- Tree Toolbar
Allows the filtering of the shown values by your own criteria
 ,
,sets a filter to only show rows with an assigned value (
 ),
),expands or collapses the list (
 )
)- Code Block
In the code block below the tree table you can express any complex mapping that does not fit into the tree table. For instance you might prefer to use the code block to assign values by using a loop statement.
Code Tab
The code tab is part of almost all inscription masks and allows the user to define the semantics (behaviour) of the corresponding process element with the built-in IvyScript.
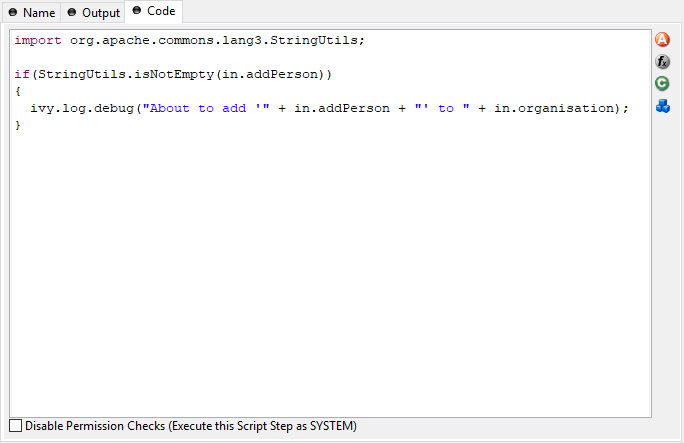
Code Tab
- Code Editor
You can write IvyScript code snippets in the part with yellow background. The editor supports code completion and error highlighting. If the background color changes to red, the code contains an error.
Tip
For more information about IvyScript, see IvyScript.
- Attribute Browser
Here you have access to the local process data in the scope of the element such as the
in- andout-variables and other parameters. See Attribute and Method Browser for more information.- Function Browser
Here you have access to some of the most important mathematical functions and to the whole environment of the process such as the request and response properties, the application the process belongs to and many more. Click Function Browser for more information.
- Data Class Browser
Here you have access to all data classes in the scope of the process element. This includes the built-in Ivy data types such as
String,Number,DateTimeor evenList. See Data Type Browser for more information.
Start Tab
The start tab defines the name and the input parameters to start the process. The signature is a definition of the name with the parameter types and its order. Elements like Call Sub or Trigger Step are referenced to this signature.
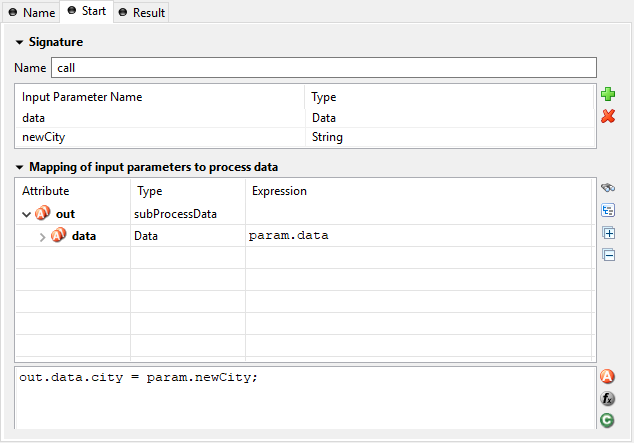
Start Tab
- Signature
Displays the current signature. Namespaces of the parameter types are not displayed, but they are still a part of the signature, that identifies a start uniquely.
- Name
Signature name is case sensitive and can only contain letters (a-Z), numbers (0-9) and underscores (_).
- Definition of input parameters
Defines the input parameter of the interface. The type of the parameters and its order is used for the signature. Changing the order or the type, changes also the signature. All referenced elements have to be updated. The list may be left empty if the operation does not require any input parameters. To add a new parameter, click the green plus icon and specify the name and type of the parameter.
- Mapping of input parameters
The input parameters defined above are available as fields on the
paramvariable. You can assign the parameter values to the internal data fields in the table.Note
The reason why you have to assign the incoming parameters to local data is to keep the implementation independent from the declaration.
Tip
You may already specify the type of the parameter here by adding a colon ‘:’ to the parameter name, followed by desired type (e.g.
myDateParameter:Date). When only adding a colon to the name without a type, the default data type will be String.- Code
In this code block you can insert any logic needed. The context is the same as in the Mapping of input parameters.
Note
The reason you have to assign the incoming parameters to local data is to keep the internal implementation independent from the signature declaration. The mapping of parameters serves as a flexible adapter mechanism. The implementation can be changed (rename data, use different data types, etc.) without changing the signature. That way none of the clients of the process have to be changed as long as only the implementation changes and the signature stays.
Note
Only the defined input parameter on the signature can be assigned to the process data. The internal process data is hidden and encapsulated from the environment. This makes it impossible to inject unintended, insecure data into the process data.
Result Tab
This tab is used to define the values that will be returned to the caller when the process ends. All logic in this tab will be executed when the end element is reached. E.g. when the User Dialog Exit End is reached.
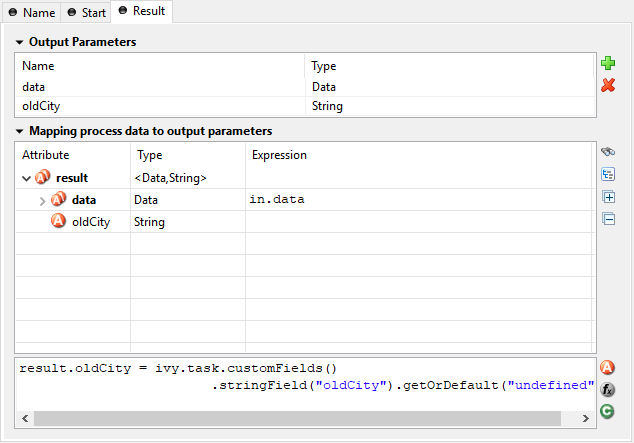
Result Tab
- Output Parameters
This table is used to define the output parameters of the operation. The list may be left empty if the operation does not return any data. To add a new parameter, click the green plus icon and specify the name and type of the parameter.
- Mapping of process data
For each defined output parameter you must now specify the value that will be returned. In most cases, this is a process attribute. However you may specify any valid IvyScript expression.
- Using the defined return parameters
The declared return parameters are shown in the table as fields of a
resultvariable (none if the defined return value isvoid).
Data Cache Tab
Process activities that read data from an external system can cache values of previous executions in the memory and re-use them on follow up executions. This is an optimization for external systems that execute expensive operations or have slow response times.
For more information about this topic, please refer to the Data Caching section.
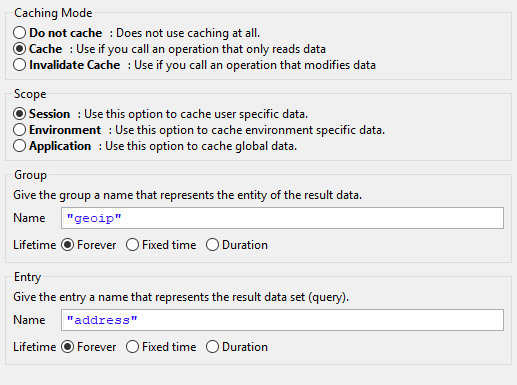
Data Cache tab
- Caching Mode
Do not cache: Does not use the data caching mechanism at all, the element is executed normally. This is the default setting for all elements.
Cache: Uses the data caching mechanism to execute the element. First the whole data cache is searched for the entry described below in the Group/Entry part. If found, the cached value is returned and the execution of the element ends. If not found, the element is executed normally, but in the end the result is stored in the data cache.
Invalidate Cache: Explicitly invalidates the data cache entry specified in the Group/Entry part. Use this when your element performs a write operation that changes data which is cached. The step is executed normally, but in addition the specified data cache entry is invalidated.
- Scope
Cache entries depend from the active environment and are always bound to their scope.
Session: the cache entry is linked to the currently logged in user (i.e. is specific for each user and is invalidated when the user logs out).
Environment: the cache entry is linked to current environment.
Application: the cache entry is linked to the Application
Warning
Use caches sparingly and with precaution! If you cache results from process steps with huge results (in terms of memory usage), your memory can fill up very fast. This can even get worse if you frequently use the session scope and the result is cached multiple times (once for each session i.e. user)
- Group
Name: Cache entries need a group name. Several entries can share the same group in order to invalidate multiple entries at the same time.
Lifetime: Groups can be invalidated either on request (see Caching Mode: Invalidate Cache), at a specific time of the day or after a configurable period of time. Invalidating a group always means to remove all its entries from the cache.
- Entry
Name: Must be unique within the group but you are allowed to have multiple entries with the same name in different groups. Use always the same entry names (as well for the group) if you want to use the same data cache entry in multiple process steps.
Lifetime: Single cache entries can be invalidated either on request (see Caching Mode: Invalidate Cache), at a specific time of the day or after a configurable period of time.
Case Tab
Every time a process is started a case is created. This tab allows you to define additional information for the cases. The information defined on this tab has no effect how Axon.ivy treats the cases. But they can be accessed through the Public API, which allows you to use them for example to filter the task list.
You can define the name, the description and the category for the corresponding case.
Note
Look at the workflow concept for some more information about categorization.
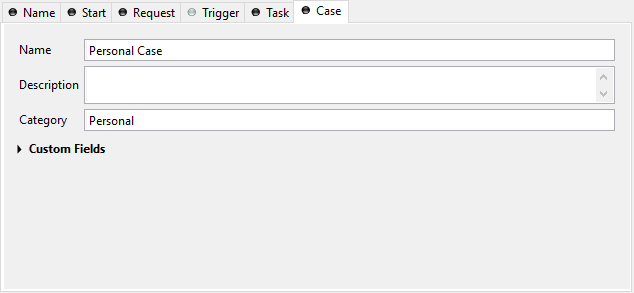
Case Tab
- Case Custom Fields
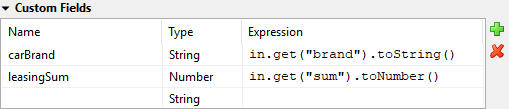
Task Custom Fields
Here you can set additional information for the created case. The set values are only informational and have no effect on how this case is treated by Axon.ivy. These custom fields can easily be queried on case user interfaces to allow sorting and filtering.
Task Tab
This tab defines the parameters for the tasks created by the Task Switch. The task tab is used by Task Switch Event, Task Switch Gateway and User Task.
Name, description: of the task that appear in the task list of the addressed role or user.
Category: It is recommended practice to define and reference the text from the CMS. See here.
Responsible: The role or user to assign the task
Use Role from Attr. or User from Attr. (as String), if the role or user must be set dynamically during process execution.
Use Role if you know the responsible role when editing the element.
The role SYSTEM means that no human intervention is required. The system executes the new task automatically.
The role CREATOR means that the user who has started the current case is responsible for the new task.
The role SELF means that the user who worked on the previous task is also responsible for the new task.
Note
A user can be informed by mail if a new task has been created for him. User mail notification can be configured on the Axon.ivy Engine. See Email Notifications.
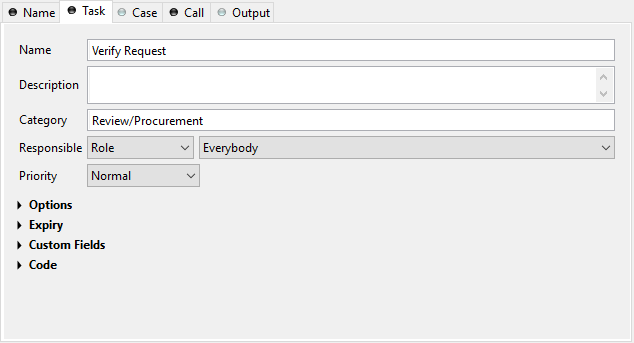
Task tab
- Task Options

Task Options
Skip Tasklist
Normally a user interaction ends at a Task Switch element. It will be redirected to the task list or an end page is shown. If Skip tasklist is activated for a task the user interaction may not end at the Task Switch element. It is automatically redirected to this new task marked with Skip tasklist. But only if it is allowed to work on the task and the Task Switch is not waiting for any other tasks to finish.
Onle one task of a Task Switch element can activate Skip tasklist.
Delay
The task can be blocked before a user can work on it. So the user will not see the task in his tasklist or get any notification about its existance until the delay period is over. This ivyScript expression defines the Duration the task is blocked.
- Task Expiry
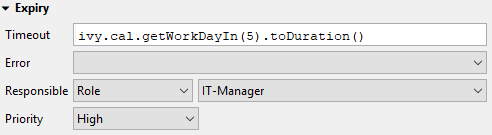
Task Expiry
Timeout
An ivyScript expression defines the Duration until the task will expire. If that happens the escalation procedure defined by the following parameters is executed.
Note
If a Delay is defined, the expiry timeout begins after the Delay.
Error
Executes an Error Start that compensates the expired task. Here you can implemented any custom behaviour and access the full workflow API.
Responsible
Defines the role or user to reassign the task to after it has expired.
Use Role from Attr. or User from Attr. (as String), if the role or user must be set dynamically during process execution.
Use Role if you know the responsible role when editing the element.
The role SYSTEM means that no human intervention is required. The system executes the new task automatically.
The role CREATOR means that the user who has started the current case is responsible for the new task.
The role SELF means that the user who worked on the previous task is also responsible for the new task.
Priority
Defines the new Priority of the task after it has expired.
- Task Custom Fields
-
Task Custom Fields
Here you can set additional information for the created task. The set values are only informational and have no effect on how this task is treated by Axon.ivy. These custom fields can easily be queried on task user interfaces to allow sorting and filtering.
- Task Code

Task Code
This is a post construct code block for the Task that is defined in this tab. The created Task is provided as variable called
task. Classically you can use is to call custom API that relates to the task, but there is no feasible UI element available to configure it. E.g. the BusinessCalendar of the created Task could be defined in this place. Or if you need to define Custom Fields with dynamic keys out of a third party source you’d rather do this in this code block than with the ui table above where the key names and types are static.